01 // The Goal
Venture capital is where tomorrow's tech giants show up first — Google, Tesla, Uber, Doordash all moved through multiple VC rounds before they were household names. Tracking that activity reveals developing trends in technology, culture, and market direction earlier than almost anywhere else.
VCNewsDaily publishes free details on the 30 most recent funding rounds at any time, with a paid catalog behind that. I set out to do the reverse of their paywall — programmatically read the public HTML, clean it, and store it in a format that supports real analysis: SQL tables with proper datatypes.
02 // Why It Matters
Once this data is warehoused cleanly, teams across three disciplines can use it:
- PE/VC analysts — spot acquisition targets and emerging competitors before the mainstream picks them up.
- Product R&D (biotech, aerospace, electronics) — identify upcoming technologies that could cross into their own domains.
- Business development — generate qualified lead lists filtered by industry, region, or funding stage.
This project isn't the analysis layer. It's the scaffold that makes the analysis layer possible.
03 // The Source
VCNewsDaily's website is well-suited for visual browsing — but without buying the catalog, their search tools cap you at the last 30 rounds. Scraping the raw HTML gets past that ceiling.
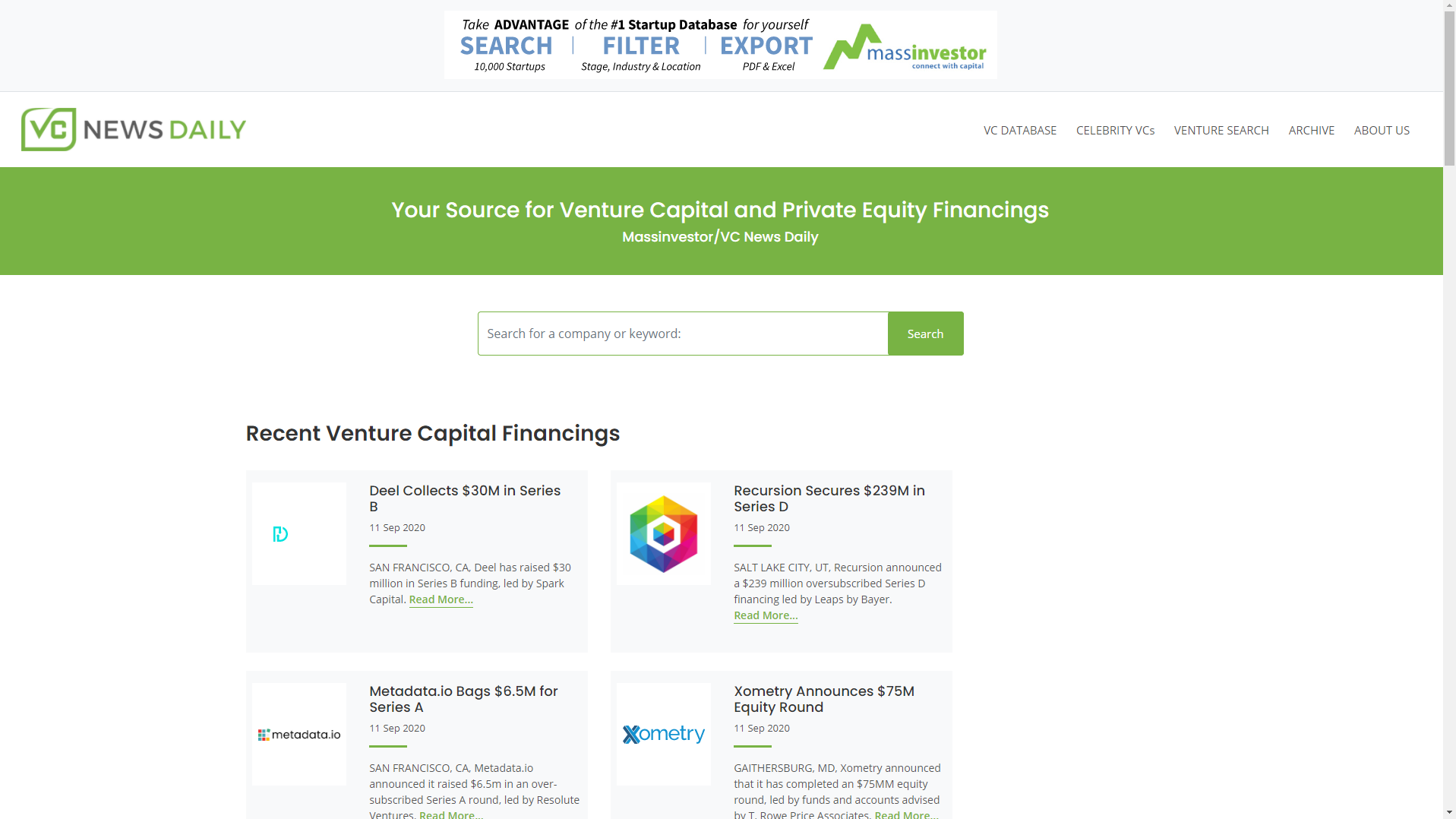
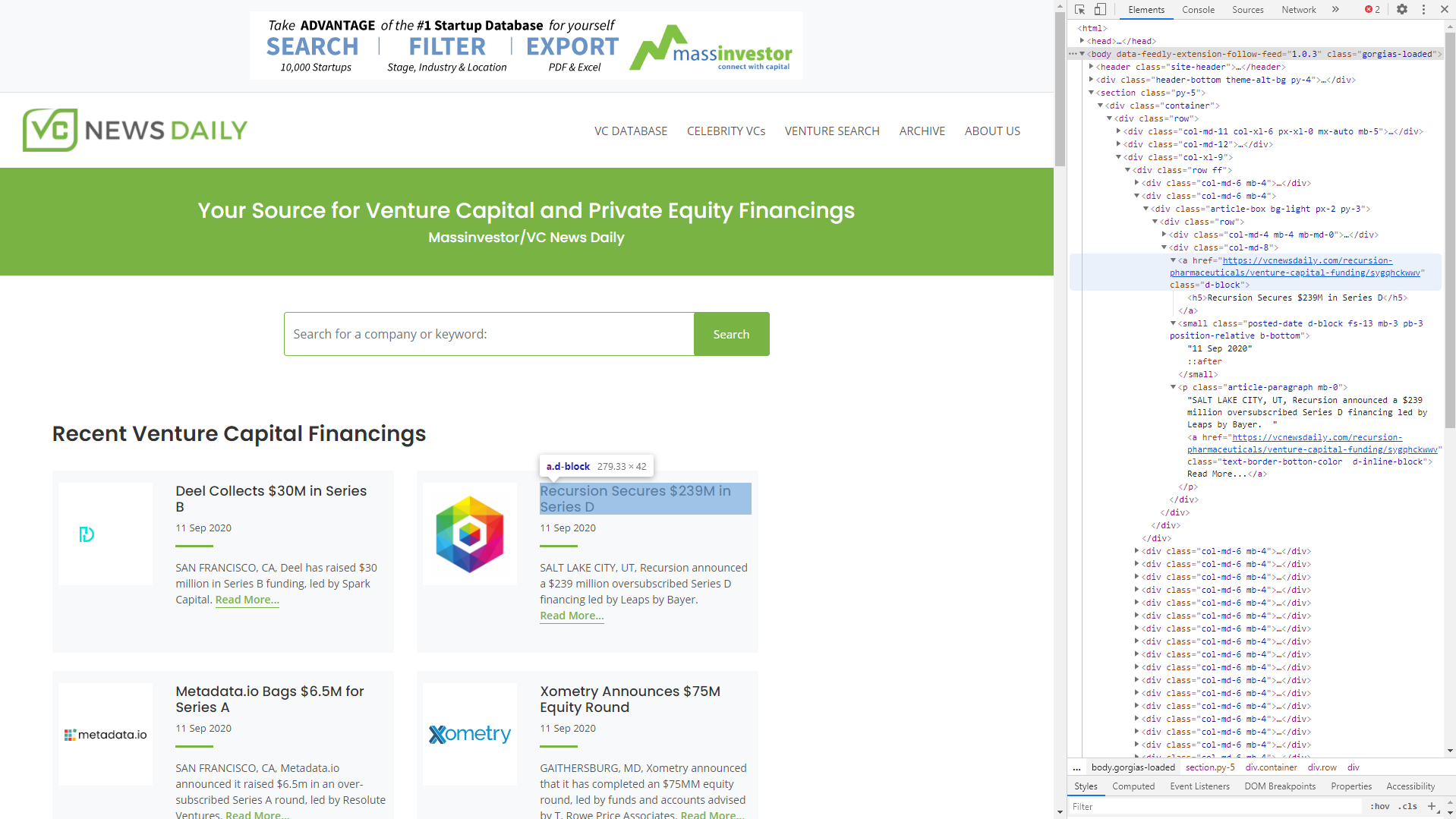
04 // Extract · Three Pages per Round
Each funding round on VCNewsDaily spans three linked pages: a general summary, the funding-round details, and the company profile. The Python scraper walks all three per round and stitches the fields back together by key.
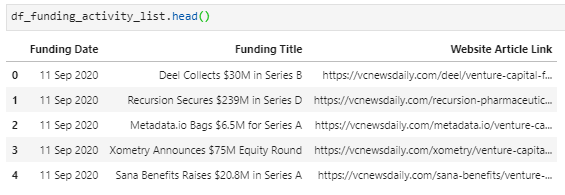
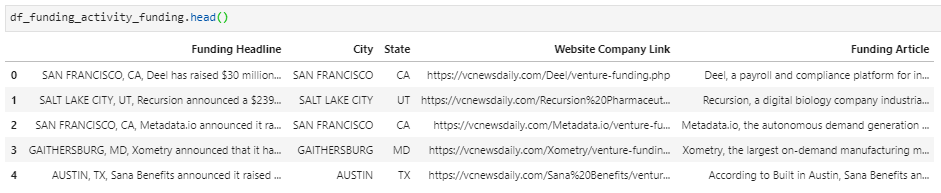
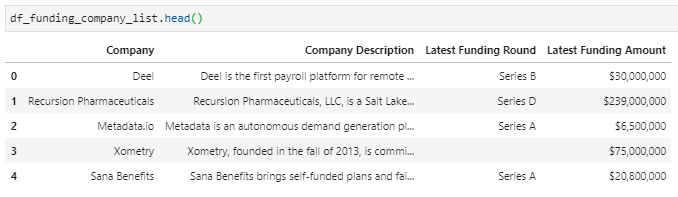
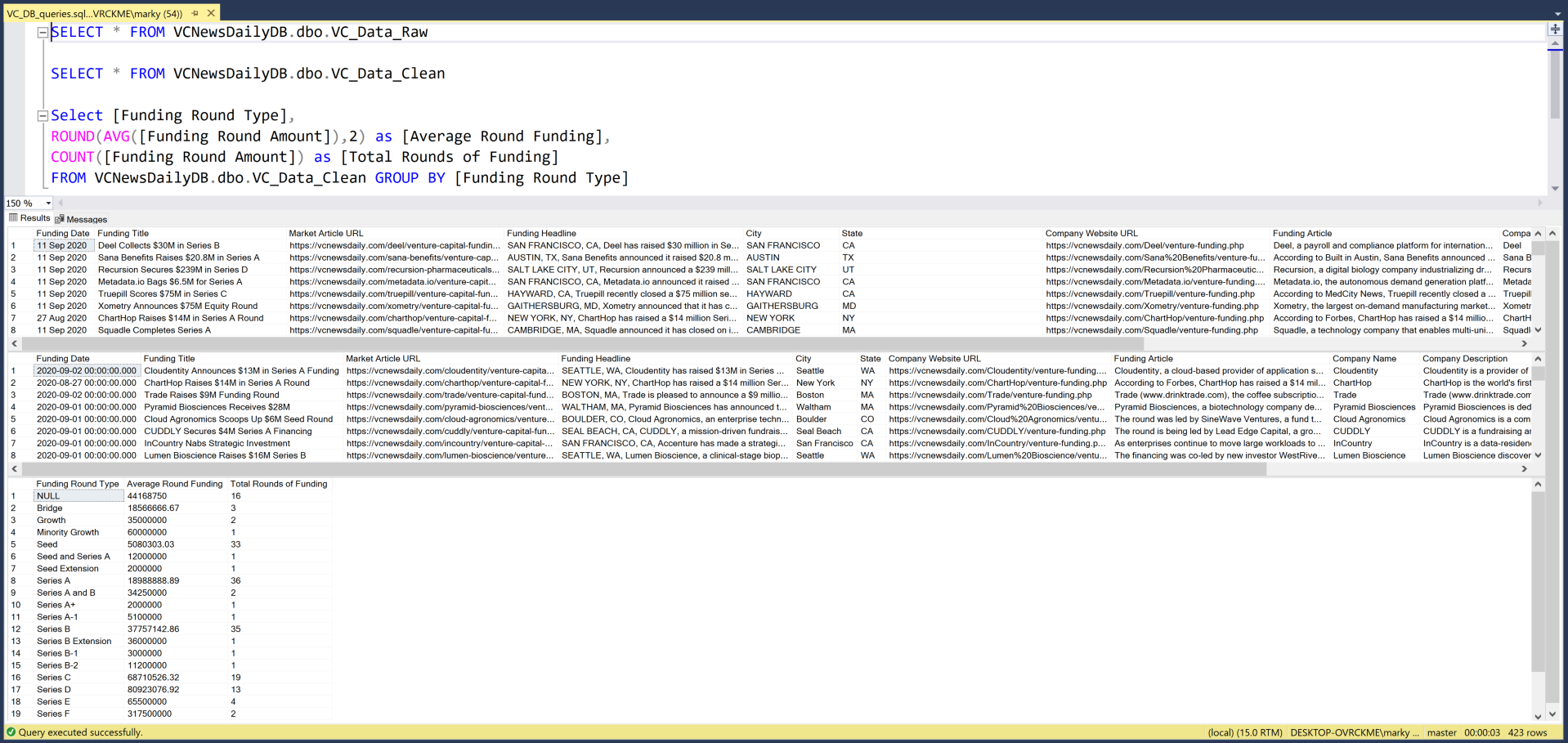
05 // Transform · From Raw to Clean
Raw scrape output gets merged row-by-row into a single raw dataframe — messy strings, inconsistent date formats, currency mixed into text, everything still looking like HTML.
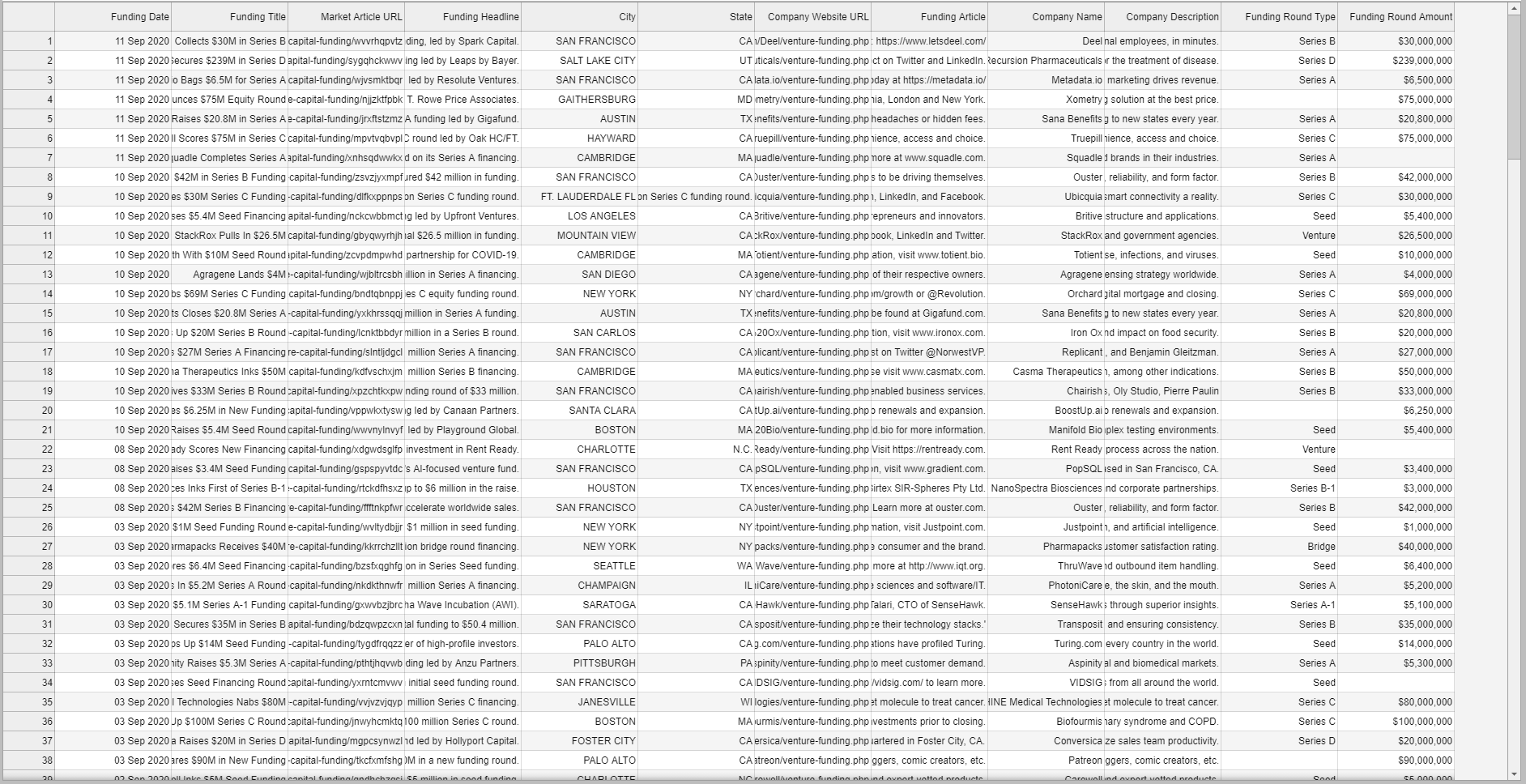
Pandas then normalizes dates, strips currency symbols to numeric amounts, standardizes company names and categories, and drops duplicates. The cleaned dataframe is ready for warehousing.
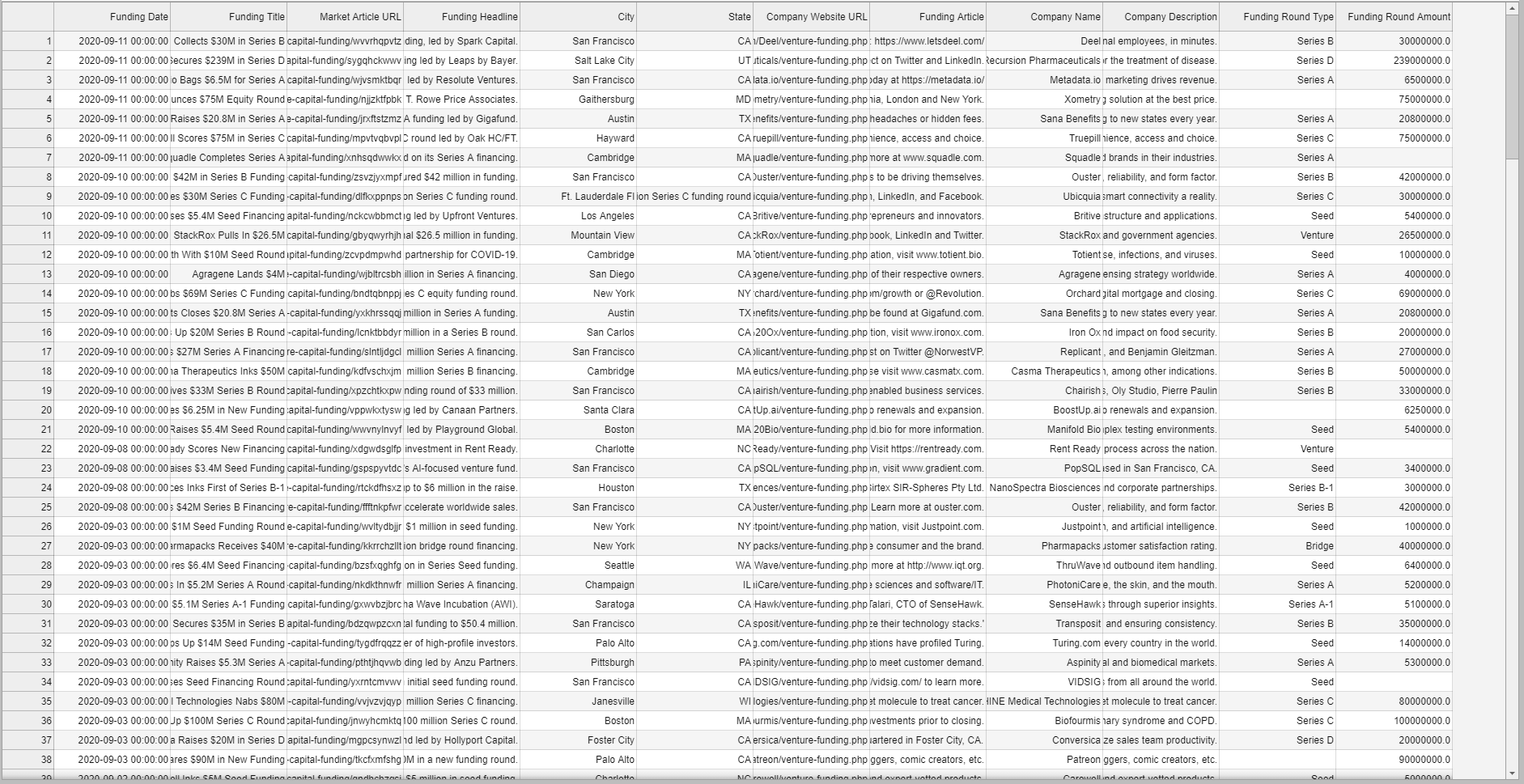
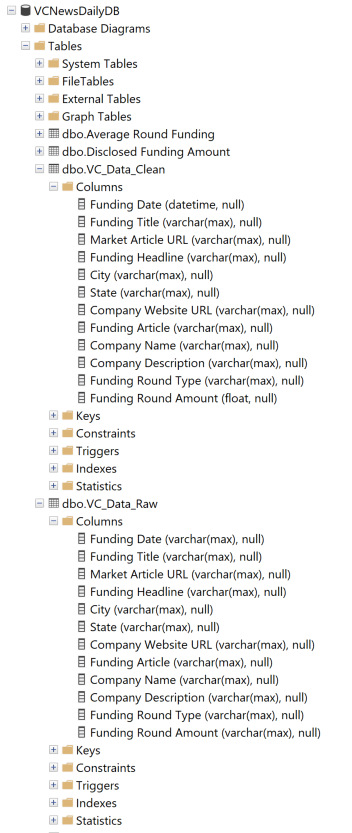
06 // Load · Into SQL Server
The clean dataframe is written into MS SQL Server with explicit datatypes — dates as datetime, funding amounts as decimal, categorical fields as nvarchar with bounded length. Typed storage is what makes the next step (calculations, predictive modeling, joins with external datasets) actually practical.
07 // What I Took From It
- ETL fundamentals — extract / transform / load as three distinct concerns, each worth doing well on its own before you chain them.
- Datatype discipline — loading strings into SQL is easy; loading the right types makes every downstream query faster and every downstream report correct.
- Scaffolding beats one-shot analysis — this repo's real value isn't the 2020 snapshot of fundings, it's the reusable pattern for scraping → cleaning → warehousing any similar public dataset.
The arc from this project to later work (the Threat-Intel ETL, the KPMG analysis) is a straight line: same three stages, bigger data, better tooling.
08 // Try It
Source notebook on github.com/marky224. Requires Python 3, BeautifulSoup, pandas, and a SQL Server instance (or SQLite with minor adjustments).